11.
(a)
Although there is a strong positive linear correlation (r = 0.970) between X values and Y values, the residual plot shows a pattern suggesting that the linear fit is not appropriate:
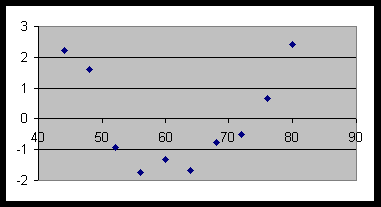
(b)
yhat = a + bx
yhat = -13.91569091 + 0.525677273(56.5)
yhat = 15.785
(c)
linear fit between x and log y yields a = 0.495316683, b = 0.012139633
log yhat = a + bx
10log yhat = 10a + bx
yhat = (10a) (10bx)
yhat = (10a) (10b)x
Answer: yhat = 3.128359703 (1.028346877)x, which has the required form. [Note that a and b in the required form are different from the a and b in the linear regression.]
(d)
- ExpReg gives same values: yhat = abx, where a = 3.128359703, b = 1.028346877.
(e)
- Using yhat = abx = 3.128359703 (1.028346877)x from (c), we have
yhat = 3.128359703 (1.028346877)56.5 = 15.178
(f)
- Since the X values are equally spaced, we can look at ratios between successive Y values:
1.127063139
0.96823183
1.101872599
1.183963977
1.107900871
1.166823542
1.112223593
1.139681727
1.143712799
These values are close enough to suggest an approximately constant ratio, which is the hallmark of an exponential model.
However, the residual plot is still not very random:
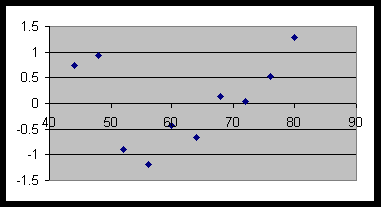
Although the pattern is less pronounced than before, there is still a lack of randomness. [Neither exponential nor power regression gives a very good fit. However, both give a lower SSE than the original linear fit, which is certainly a good thing. How would we calculate SSE, by the way? See below for answer.]
How to calculate SSE efficiently on your calculator:
Perform 1-Var Stats on your residuals (called RESID if you are using a built-in regression). Unfortunately, although it would seem logical that you could punch in STAT CALC 1-Var Stats 2nd LIST RESID ENTER, the word "RESID" is a reserved word and cannot be used for 1-Var Stats. However, you can "STO" the RESID list into a new list called, say, R4, and then punch in STAT CALC 1-Var Stats 2nd LIST R4 ENTER. The SSE would be shown as S x2, which of course, should never be confused with (S x)2.
What if you are using a "custom" regression where you have to calculate residuals manually? Suppose that your residuals are stored in L5. Then you would punch STAT CALC 1-Var Stats L5 ENTER. As before, you would read the SSE as S x2.